mebioda
Versioning
- Version management
- Backup
- History
- Provenance
The problem: how to manage ongoing change

(source: PhD comics)
- Documents go through many versions, over the course of years
- Meanwhile, related files (data, scripts, figures, bibliographies, etc.) are changing as well
- You are probably collaborating with others (coauthors, reviewers, editors, etc.)
- You probably will not know ahead of time which will be the “final” document version
Part of the solution: work in a project-oriented manner
WS Noble, 2009. A Quick Guide to Organizing Computational Biology Projects. PLoS Computational Biology 5(7): e1000424. doi:10.1371/journal.pcbi.1000424
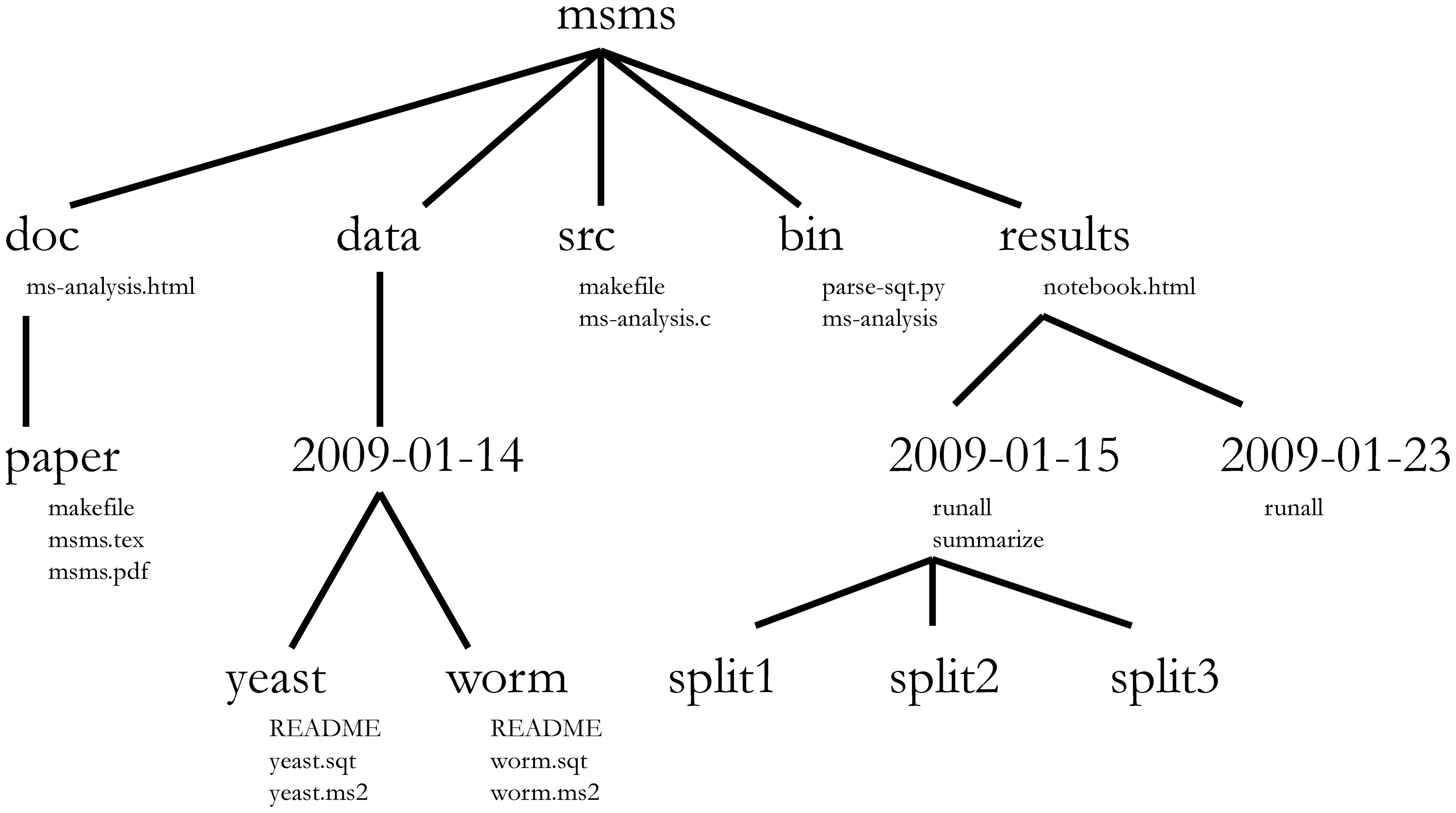
- Organize your work in projects (e.g. GTD philosophy)
- Follow consistent naming schemes (e.g. ISO-8601 date format)
- This allows us to plan for open-ended change by date-stamping folders, but:
- How to deal with mistakes?
- How to “undo”?
- How to collaborate?
Backing up and sharing your projects
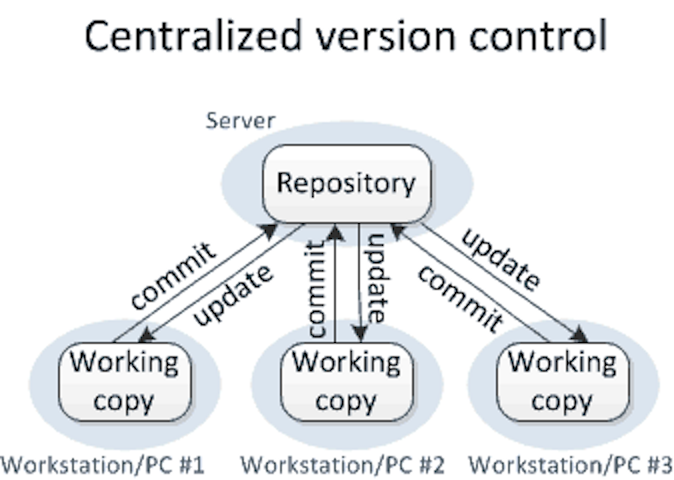
- We are doing local operations (e.g. writing, editing (code, data), analyzing) on a local copy that is backed up to a remote folder
- This is roughly the workflow in dropbox, google drive (where synchronization happens as a background process) as well as in centralized version control systems such as cvs and svn (where synchronization happens after a “commit”).
- However, this easily results in conflicts:
- Multiple people work on their local copies of different files at the same time
- When synchronization happens, different files (and their versions) may arrive in the wrong order
- Relationships between files may become scrambled, race conditions may arise, etc.
The distributed approach
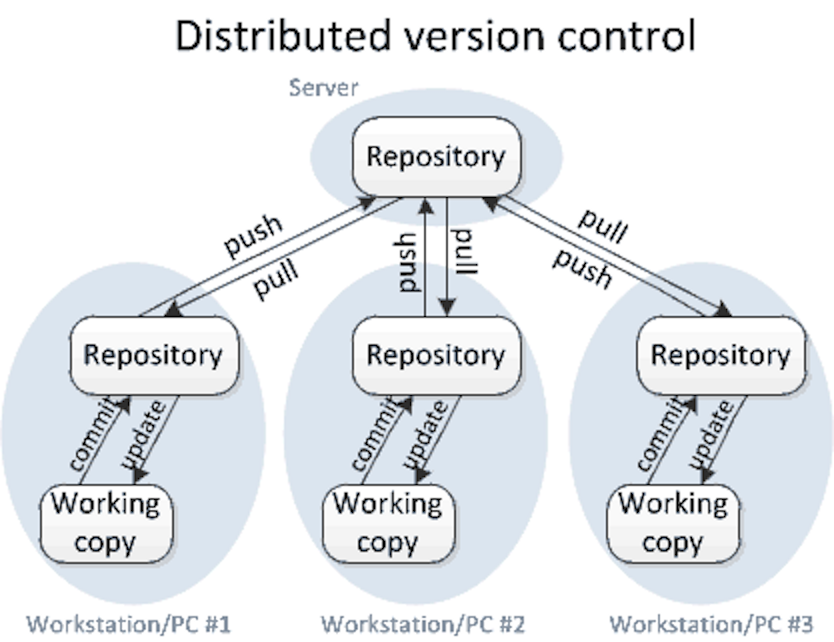
- Everyone takes individual ownership of the consistency of the entire project
- Only after all local changes have been comitted to the local repository do we push the repository “upstream”
- If the upstream repository has changed since the last time the local was synchronized, potential conflicts need to be resolved first
git - distributed version control
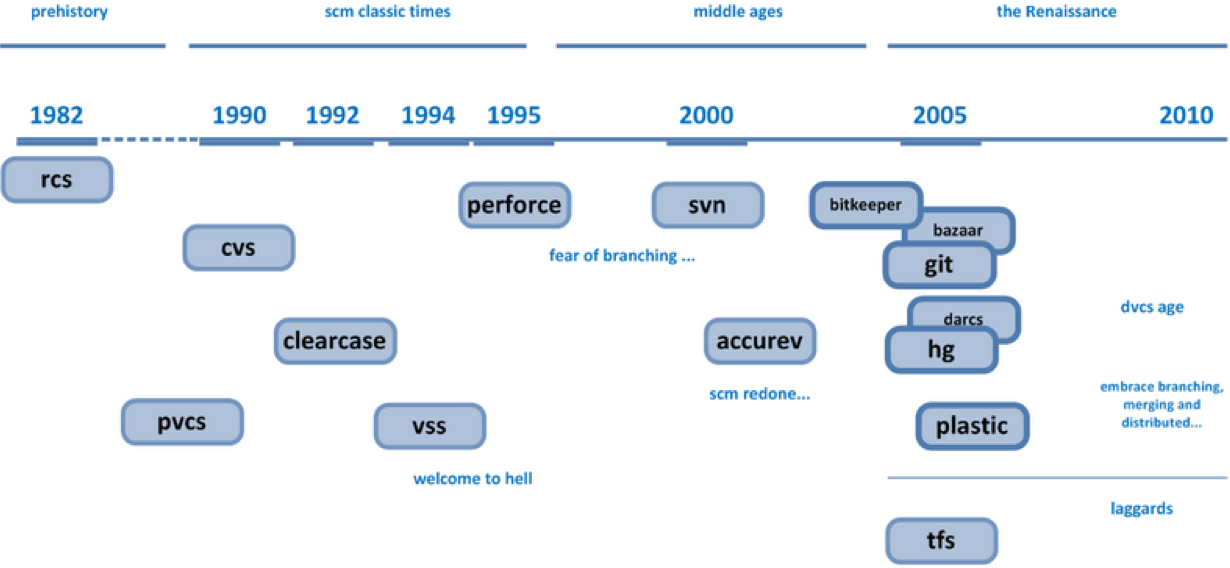
gitis an approach to distributed version control that was developed to manage the contributions of thousands of people to the source code of Linux.- There is a standard command line tool for all major operating systems. There are also graphical interfaces (which are not that useful), and plug-ins for development tools (such as RStudio, which is very useful)
- Many websites provide remote hosting for git projects. GitHub is a very popular one, but there are others, such as BitBucket or SourceForge
git workflow - starting a repository
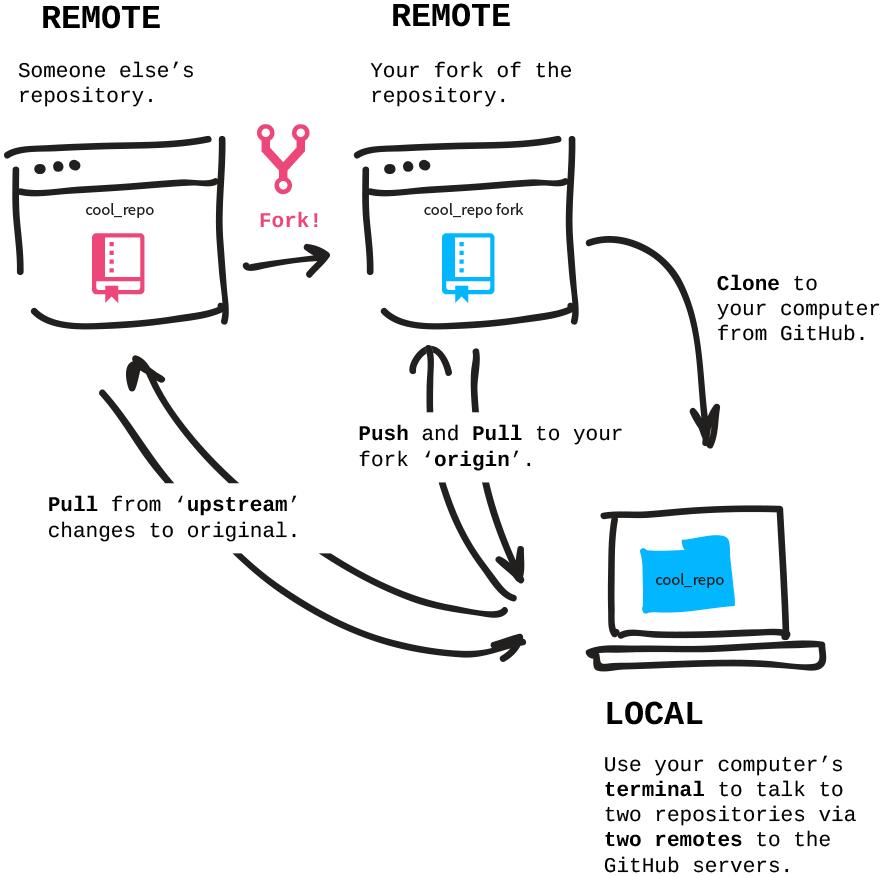
- The first step is to create a repository. This can be:
- A new repository that you start locally (e.g.
git init .) - A repository you start remotely (e.g. “New repository”, top-right menu on GitHub)
- A repository that you fork remotely (e.g. “Fork” button, top-right, on GitHub)
- A new repository that you start locally (e.g.
- Then, if the repository was started or forked remotely you want a local clone, e.g.:
# using HTTPS:
$ git clone https://github.com/<user name>/<project name>.git
# using SSH:
$ git clone git@github.com:<user name>/<project name>.git
git workflow - adding a file

Let’s say I have a file data.tsv that I want to add to a repository:
# I have placed my file in my local repository and check to see if git notices:
$ git status
# response:
On branch master
Your branch is up-to-date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
data.tsv
Now add it:
$ git add data.tsv
$ git status
# response:
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: data.tsv
So now the file is ready to be “committed”. Let’s commit it to our local repository, and
add a message (-m 'message text goes here):
$ git commit -m 'adding file data.tsv' data.tsv
# response:
[master d588593] adding data.tsv
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 doc/week2/w2d3/data.tsv
$ git status
# response:
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
Now our file has been incorporated in our local repository. If this is a fork of a remote repository we can “push” the file upstream to the remote repo:
$ git push
# response:
Counting objects: 5, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 455 bytes | 455.00 KiB/s, done.
Total 5 (delta 4), reused 0 (delta 0)
remote: Resolving deltas: 100% (4/4), completed with 4 local objects.
To github.com:naturalis/mebioda.git
0f031d6..d588593 master -> master
Distributed version control: why?

- Infinite undo, all the way to the beginning of the project
- Backups on the servers of the version control host (e.g. github)
- Explicit history with messages explaining why files were changed and ways to tag specific versions
- Distributed collaboration including mechanisms for experimentation (branches) and resolving conflicts
In addition, GitHub provides for a lot of functionality on top of git:
- Project management tools, such as an issue tracker
- Ways to work in the browser instead of the command line (e.g. to upload or edit and commit without the command line)
- Ways to test code automatically
- A facility to give a DOI to a specific version